Primary Research Projects
Flow-Mediated Collective Olfactory Communication in Honeybee Swarms
BioRxiv Preprint
Bee detection and classification. See video here.
Agent-based modeling. See video here.
Real-Time Audio-Visual Speech Enhancement [Microsoft Research]
ICASSP 2020 paper
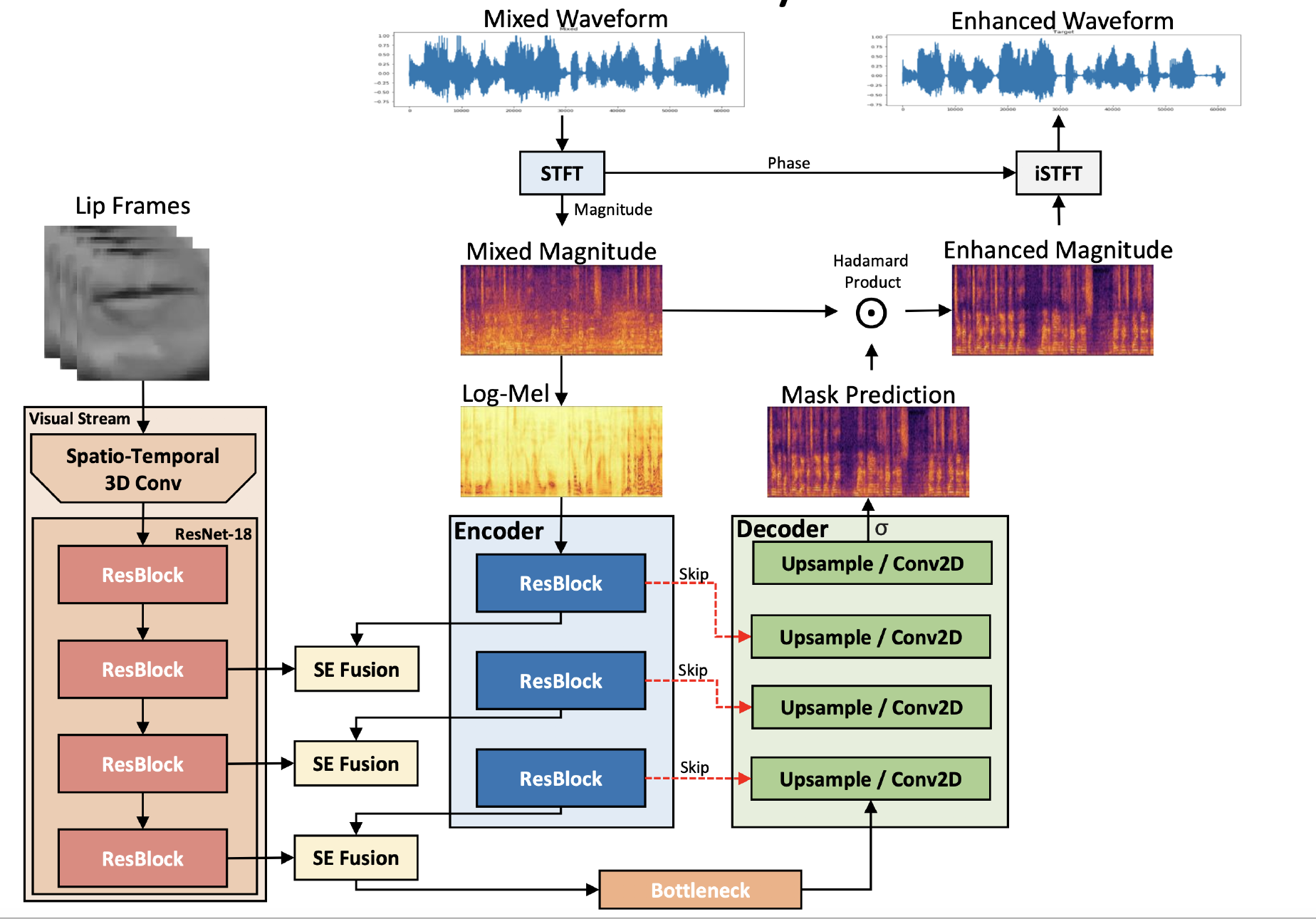
Abstract
The goal of audio-visual speech enhancement (AVSE) is to supplement audio-only information with visual information, such as target speaker’s lip movements, to improve the intelligibility and overall perceptual quality of noisy speech signals. We propose a new mechanism for audio-visual (AV) fusion that leverages a cross-modal squeeze-excitation (SE) block for speech enhancement: AV(SE)^$. The fusion block is adaptable to any feature layer of the audio and visual networks and significantly reduces model parameters as compared to standard AV fusion methods of channel-wise concatenation without loss of performance. We show that AV(SE)^$ with time-based gating across multiple feature layers outperforms baseline methods of single-point, channel-wise concatenated AV fusion on objective evaluations.
MMTM: Multimodal Transfer Module for CNN Fusion [Microsoft Research]
CVPR 2020 paper
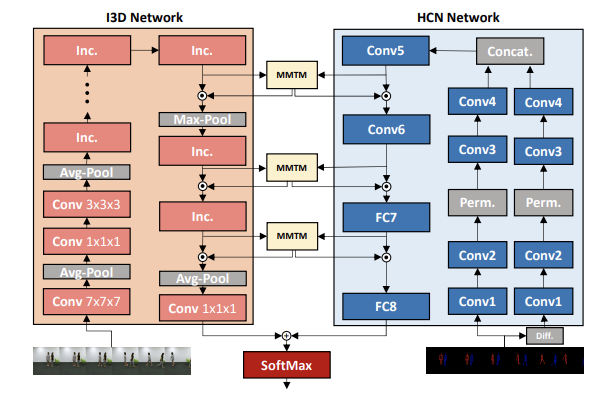
Abstract
In late fusion, each modality is processed in a separate unimodal Convolutional Neural Network (CNN) stream and the scores of each modality are fused at the end. Due to its simplicity late fusion is still the predominant approach in many state-of-the-art multimodal applications. In this paper, we present a simple neural network module for leveraging the knowledge from multiple modalities in convolutional neural networks. The propose unit, named Multimodal Transfer Module (MMTM), can be added at different levels of the feature hierarchy, enabling slow modality fusion. Using squeeze and excitation operations, MMTM utilizes the knowledge of multiple modalities to recalibrate the channel-wise features in each CNN stream. Despite other intermediate fusion methods, the proposed module could be used for feature modality fusion in convolution layers with different spatial dimensions. Another advantage of the proposed method is that it could be added among unimodal branches with minimum changes in the their network architectures, allowing each branch to be initialized with existing pretrained weights. Experimental results show that our framework improves the recognition accuracy of well-known multimodal networks. We demonstrate state-of-the-art or competitive performance on four datasets that span the task domains of dynamic hand gesture recognition, speech enhancement, and action recognition with RGB and body joints.
Convolutional Bipartite Attractor Networks
paper
Abstract
In human perception and cognition, a fundamental operation that brains perform is interpretation: constructing coherent neural states from noisy, incomplete, and intrinsically ambiguous evidence. The problem of interpretation is well matched to an early and often overlooked architecture, the attractor network—a recurrent neural net that performs constraint satisfaction, imputation of missing features, and clean up of noisy data via energy minimization dynamics. We revisit attractor nets in light of modern deep learning methods and propose a convolutional bipartite architecture with a novel training loss, activation function, and connectivity constraints. We tackle larger problems than have been previously explored with attractor nets and demonstrate their potential for image completion and super-resolution. We argue that this architecture is better motivated than ever-deeper feedforward models and is a viable alternative to more costly sampling-based generative methods on a range of supervised and unsupervised tasks.
Real-Time 3D Object Retrieval and Pose Estimation from 2D RGB Images [Microsoft Research]
Abstract
Three-dimensional (3D) model retrieval and pose estimation are crucial tasks with myriad applications for autonomous vehicle navigation, augmented reality, robotics, etc. However, learning a mapping between 2D representations of an object and its 3D counterpart is non-trivial. Recent works approach this problem utilizing deep learning models to learn representations between some combination of 3D CAD models, their 2D projection (render) in either RGB or RGBD, 3D voxel grids, and real object images in either RGB or RGBD. However, differences between real and rendered images — known as the reality gap — present significant challenges for model retrieval and pose estimation. In this paper, we present our approach for fast, simultaneous 3D model retrieval and pose estimation from single RGB images utilizing multi-view deep metric learning and fully convolutional networks (FCNs). We show that our viewpoint estimation method outperforms state-of-the-art keypoint methods on Pascal3D+. Additionally, our method is category-agnostic, scalable, and allows for real-time 3D-model-to-real-object alignment.


Fully Bayesian Human-Machine Data Fusion for Robust Dynamic Target Surveillance and Characterization
AIAA 2019 paper
See video here.
Abstract
This work examines the problem of rigorously characterizing and fusing observations provided by human operators with probabilistic information extracted by an automated data fusion system, in the context of dynamic multi-target tracking and surveillance. This task is characterized by two major theoretical and practical challenges. Firstly, stand-alone human operator observation error characteristics can be very difficult to parameterize and calibrate a priori. Secondly, it is common for human reports to be dependent on other information that may already have been fused elsewhere in the data fusion pipeline; in particular, successive single target observations from one operator are, in general, not conditionally independent of one another. A new hierarchical fully Bayesian probabilistic model is developed to explicitly account both for uncertainties in ‘human sensor’ quality and Markovian conditional dependencies in successive target characterization reports. This hierarchical model is then used to perform online Bayesian inference via Gibbs sampling to simultaneously update the data fusion system’s knowledge of human sensor characteristics and target type probabilities (i.e. simultaneous online human sensor calibration and target state estimation). Practical methods for approximating high-dimensional human sensor parameter posterior distributions via Dirichlet pdf moment-matching and parameter-tying are also developed, and shown to provide significant computational speedups for little/no noticeable information loss. Results with different combinations of simulated operator profiles and automated fusion system target characterization baselines show that fully Bayesian fusion can simultaneously improve machine-based target characterization performance with variable human operator profiles, while accounting for uncertain operator characteristics.
In Automation We Trust: Investigating the Role of Uncertainty in Active Learning Systems
paper
Abstract
We investigate how different active learning (AL) query policies coupled with classification uncertainty visualizations affect analyst trust in automated classification systems. A current standard policy for AL is to query the oracle (e.g., the analyst) to refine labels for datapoints where the classifier has the highest uncertainty. This is an optimal policy for the automation system as it yields maximal information gain. However, model-centric policies neglect the effects of this uncertainty on the human component of the system and the consequent manner in which the human will interact with the system post-training. In this paper, we present an empirical study evaluating how AL query policies and visualizations lending transparency to classification influence trust in automated classification of image data. We found that query policy significantly influences an analyst’s trust in an image classification system, and we use these results to propose a set of oracle query policies and visualizations for use during AL training phases that can influence analyst trust in classification.
Virtual-to-Real-World Transfer Learning for Robots on Wilderness Trails
IROS 2018 paper
See video here.
Abstract
Robots hold promise in many scenarios involving outdoor use, such as search-and-rescue, wildlife management, and collecting data to improve environment, climate, and weather forecasting. However, autonomous navigation of outdoor trails remains a challenging problem. Recent work has sought to address this issue using deep learning. Although this approach has achieved state-of-the-art results, the deep learning paradigm may be limited due to a reliance on large amounts of annotated training data. Collecting and curating training datasets may not be feasible or practical in many situations, especially as trail conditions may change due to seasonal weather variations, storms, and natural erosion. In this paper, we explore an approach to address this issue through virtual-to-real-world transfer learning using a variety of deep learning models trained to classify the direction of a trail in an image. Our approach utilizes synthetic data gathered from virtual environments for model training, bypassing the need to collect a large amount of real images of the outdoors. We validate our approach in three main ways. First, we demonstrate that our models achieve classification accuracies upwards of 95% on our synthetic data set. Next, we utilize our classification models in the control system of a simulated robot to demonstrate feasibility. Finally, we evaluate our models on real-world trail data and demonstrate the potential of virtual-to-real-world transfer learning.
Other Projects and Interests
Computer Graphics - Natural Scene Generator


Space Habitat Design

